

How We Benchmark ASR Models: A Technical Deep-Dive into WER, CER, and Indic Dataset Methodology
Speech recognition accuracy is only as credible as the methodology used to measure it. For teams deploying ASR in production, a WER number without provenance tells you almost nothing. This document explains exactly how Gnani.ai benchmarks its ASR models: which datasets we use, why we chose them, how we compute metrics, and where pure-play ASR engines and LLM-based ASR systems diverge in ways that matter for real deployments.
Metric Fundamentals
What Is Word Error Rate (WER)?
Word Error Rate is the standard evaluation metric for automatic speech recognition systems. It measures the edit distance between a hypothesis (what the ASR system transcribed) and a reference (the ground-truth transcript), normalized by the total number of words in the reference.
The formula:
A lower WER is better. A WER of 0.0 means the transcript is a perfect match. A WER above 0.5 in production telephony environments is typically unusable.
WER is computed using the Levenshtein distance algorithm, specifically the minimum edit distance between two sequences of tokens (words, in this case). The algorithm fills a dynamic programming matrix where each cell represents the minimum number of operations required to transform one partial sequence into another. For a reference of length m and hypothesis of length n, this is an O(m × n) computation.
Metric Fundamentals
What Is Character Error Rate (CER)?
Character Error Rate applies the same Levenshtein framework at the character level rather than the word level.
WER treats this as a complete word error. CER shows 3 of 5 source characters required edits, reflecting the phonetic proximity between the two forms. For downstream NLP, the distinction matters: the speaker used colloquial Tamil; the LLM-augmented ASR returned formal register.
CER is particularly relevant for Indic language evaluation for several reasons. Indic scripts, including Devanagari, Tamil, Telugu, Kannada, Bengali, Gujarati, Odia, Malayalam, and Punjabi (Gurmukhi), are abugidas, where a single orthographic unit (akshar) encodes a consonant with its attached vowel diacritic. A single substitution at the character level may not constitute a full word error, yet it changes the meaning of the word entirely. CER captures these sub-word errors that WER would either ignore or over-penalize.
Evaluation Infrastructure
Datasets: What We Use and Why
Benchmarking without a diverse, representative dataset pool produces numbers that perform well in the lab and poorly in the field. Our evaluation dataset covers eight datasets for Hindi and nine regional Indian languages, drawing from sources that are well-established in the Indic ASR research community and available via Hugging Face.
Hindi Datasets
| Dataset | Publisher | Description | Corpus Size | Key Characteristics |
|---|---|---|---|---|
| GramVaani | IIT Bombay / GramVaani | Community radio recordings from rural India | ~1,100 hours | Noisy, dialectal, Tier 2/3 speakers |
| CommonVoice | Mozilla Foundation | Crowd-sourced read speech | ~500 hours (Hindi) | Clean, diverse speakers |
| KathBath | Microsoft Research India | Scripted and spontaneous speech | ~1,700 hours | Studio-quality, standard Hindi |
| KathBath Noisy | Microsoft Research India | KathBath with augmented noise | ~1,700 hours | Telephony noise, channel degradation |
| MUCS | IIT Madras | Multi-source Indic speech | ~200 hours | Broadcast, spontaneous, mixed conditions |
| FLEURS | Google Research | Few-shot learning evaluation resource | ~12 hours (Hindi) | Clean read speech, multilingual parity |
| IndicTTS | IIT Madras (AI4Bharat) | Text-to-speech aligned corpus | ~60 hours | Studio quality, clearly articulated |
| IITM-Eval | IIT Madras | Internal evaluation set | Proprietary size | Mixed conditions, held-out test set |
Hindi evaluation datasets used in Gnani.ai’s ASR benchmark suite.
Regional Language Datasets (Tamil, Telugu, Kannada, Bengali, Marathi, Punjabi, Gujarati, Odia, Malayalam)
For each of the nine regional languages, we use the following datasets where they are available:
| Dataset | Publisher | Notes |
|---|---|---|
| CommonVoice | Mozilla Foundation | Language-specific subsets; quality varies by language community contribution size |
| KathBath | Microsoft Research India | Coverage across 12 Indian languages including all nine above |
| KathBath Noisy | Microsoft Research India | Noise-augmented counterpart |
| MUCS | IIT Madras | Broadcast and spontaneous speech conditions |
| FLEURS | Google Research | Standardized multilingual evaluation set |
| IndicTTS | IIT Madras (AI4Bharat) | TTS-derived corpus; useful for clean baseline evaluation |
Regional language evaluation datasets used across Tamil, Telugu, Kannada, Bengali, Marathi, Punjabi, Gujarati, Odia, and Malayalam.
Evaluation Infrastructure
Choosing the Right Dataset for Your Use Case
This matters more than most benchmarks acknowledge. Aggregate WER numbers collapse across acoustic conditions that vary enormously in real deployments.
Noisy telephony and IVR deployments. KathBath Noisy is the primary reference. It simulates real-world channel degradation: G.711 codec compression, background noise, call drop artifacts. If a model performs well on KathBath Noisy, it is a credible candidate for telephony applications. MUCS adds broadcast conditions that approximate speakerphone and headset recordings.
Rural Tier 2/3 Hindi markets and vernacular voice applications. GramVaani is the dataset that separates production-grade models from those trained on clean studio speech. It contains community radio recordings from districts across UP, Bihar, Rajasthan, and Madhya Pradesh. The acoustic conditions are imperfect, the speakers are non-metropolitan, and the vocabulary skews toward agricultural and local administrative terminology. A model that degrades significantly from KathBath to GramVaani is not ready for rural India.
Clean studio-like environments. KathBath (clean split), IndicTTS, and FLEURS establish the ceiling. These datasets represent best-case conditions: studio recording, standard pronunciation, minimal background noise. Performance here is necessary but not sufficient for production claims.
Broadcast and structured spontaneous speech. MUCS covers news broadcasts, semi-structured interviews, and field recordings. Relevant for media transcription, compliance monitoring in formal meetings, and agents handling well-structured conversations.
Cross-lingual and multilingual model evaluation. FLEURS is designed for few-shot multilingual evaluation and provides a consistent evaluation framework across languages. It allows direct comparison of model performance across Hindi, Tamil, Telugu, Kannada, and Bengali using the same evaluation infrastructure.
The datasets that matter most for production voice AI in India are KathBath Noisy and GramVaani. They are the two test sets closest to the real conditions under which enterprise voice systems operate, noisy telephony on one side, dialectal spontaneous speech on the other. A model that performs credibly on both is a model that ships.
Evaluation Infrastructure
Benchmarking Infrastructure: API-Only Evaluation
All ASR providers are evaluated exclusively through their production APIs. We do not use locally-run models, custom inference setups, or batch-processing pipelines that differ from what a customer would deploy. This is a deliberate design constraint: it eliminates the possibility that evaluation-time optimizations (different batch sizes, local CUDA tuning, custom inference parameters) inflate benchmark numbers relative to what a real integration would produce.
Every audio file is submitted as it would arrive in a live system, resampled to 16kHz mono WAV where required, otherwise passed at native sampling rate. No audio enhancement, noise reduction, or pre-processing is applied before submission. The raw transcript returned by the API is captured and scored without post-processing.
This uniformity is what makes cross-provider comparison valid. If two providers return different transcripts for the same audio file, the difference reflects model capability, not evaluation setup.
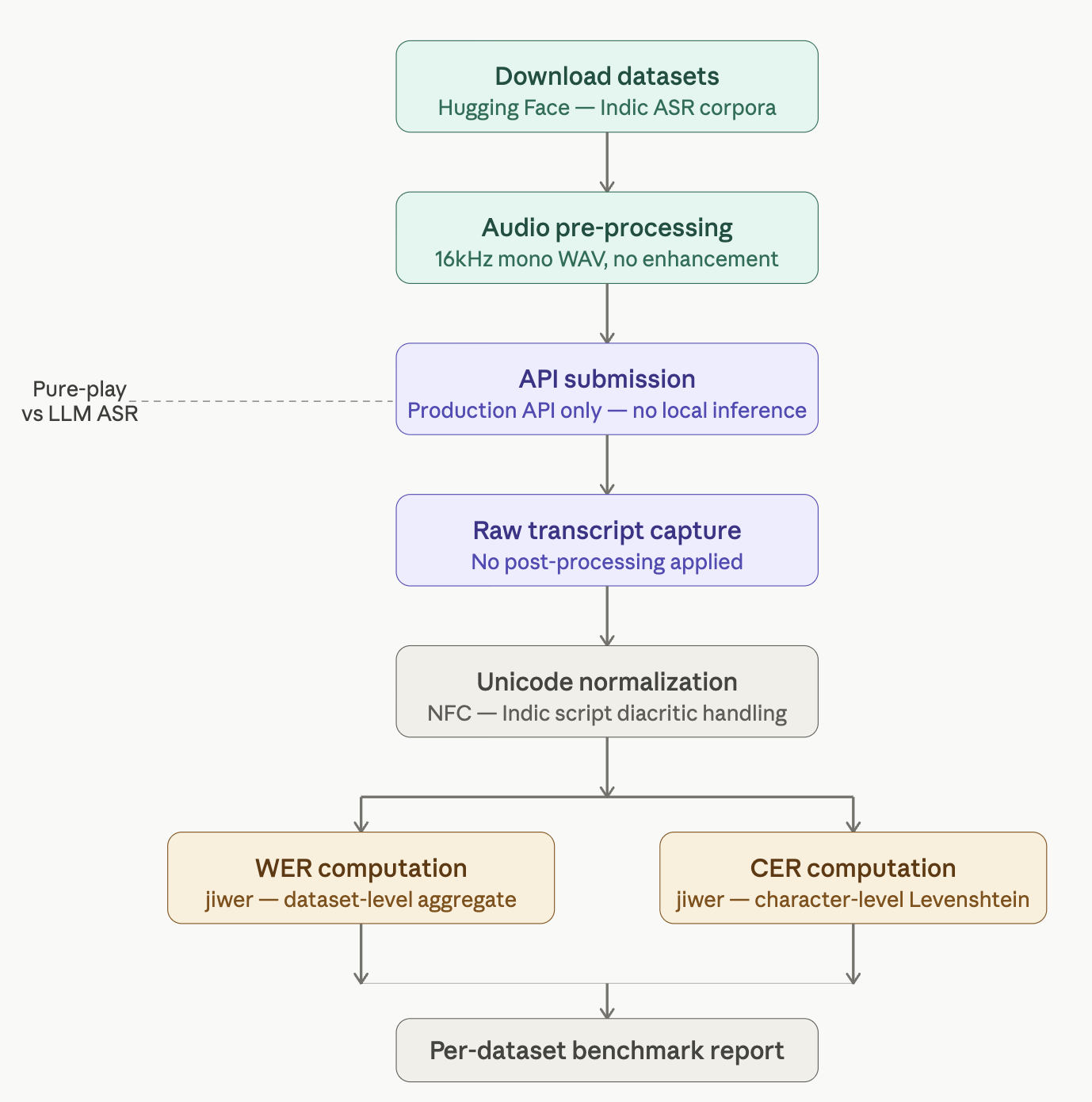
Figure 1: API-only evaluation infrastructure. All providers are assessed through production APIs under identical submission conditions, with no pre-processing or evaluation-time optimization applied.
Metric Computation
Computing WER at Scale: jiwer and Dataset-Level Aggregation
We use the jiwer Python library for metric computation. jiwer implements WER and CER according to the NIST definition, handles Unicode correctly across Indic scripts, and supports batch evaluation across entire datasets.
The core computation flow:
import jiwer transforms = jiwer.Compose([ jiwer.RemoveMultipleSpaces(), jiwer.Strip(), jiwer.ToLowerCase(), jiwer.RemovePunctuation(), jiwer.ReduceToListOfListOfWords() ]) wer = jiwer.wer( reference, hypothesis, truth_transform=transforms, hypothesis_transform=transforms ) cer = jiwer.cer(reference, hypothesis)
WER is computed at the dataset level, not as a simple average of per-utterance WER scores. Per-utterance averaging over-weights short utterances: a two-word reference where one word is wrong produces 50% WER regardless of the absolute word count. Dataset-level WER aggregates total substitutions, deletions, and insertions across all utterances and divides by total reference word count, consistent with how NIST and most published benchmarks report.
For Indic scripts, CER computation uses Unicode normalization (NFC) before character tokenization to handle composed vs. decomposed forms of vowel diacritics, which would otherwise produce spurious character-level differences.
Architectural Analysis
Pure-Play ASR vs. LLM-Based ASR: A Critical Distinction
This section addresses something most benchmark comparisons do not discuss: the architectural difference between pure-play ASR systems and LLM-based ASR systems, and why it changes what a WER number actually means.

Figure 2: Architectural comparison between pure-play ASR systems and LLM-augmented ASR. The LLM post-processing layer introduces register normalization and dialect flattening that alter what the speaker actually said.
The LLM Inferencing Layer Problem
Several ASR providers now sit an LLM layer on top of their acoustic model. The LLM post-processes the raw transcript, correcting perceived grammatical errors, standardizing register, normalizing dialect variants, and resolving ambiguous phonemes using language model probability. On clean standard-language audio, this can improve WER. In production Indic language deployments, it often makes the transcript less accurate for its actual purpose.
Consider a concrete Tamil example. A speaker says: “avanunga appadi dhaan”, a colloquial third-person plural construction using “avanunga,” which is the spoken form common in Tamil Nadu across all socioeconomic registers. An LLM-augmented ASR system, trained on written Tamil corpora that favor formal register, may return: “avargal appadi dhaan”, substituting “avargal,” the formal written equivalent.
If the ground-truth dataset labels the transcript as “avargal appadi dhaan” (as formal Tamil datasets might), the LLM-augmented system scores a lower WER. But for a collections call center or a voice bot serving Tamil consumers, this is incorrect behavior. The system has altered what the speaker said to match a written standard they did not use.
This matters in at least three ways:
Register and intent capture. In collections and customer service, the emotional register of a speaker’s language is signal. “Avanunga” and “avargal” are not interchangeable in a conversation analysis or sentiment model that sits downstream. When an LLM layer normalizes dialect to standard register, it destroys information that the downstream system needs.
Automatic respect-form inflation. Indic languages encode social hierarchy in verb conjugation and pronoun choice. LLM-augmented ASR systems, trained on formal corpora, systematically introduce formal-register honorifics that the speaker did not use. A customer using informal Tamil or colloquial Hindi with a voice agent gets their speech transcribed as formal speech directed at a superior. The literal transcript no longer represents what the speaker said.
Small utterance suppression. Short utterances, including single-word acknowledgments, affirmations, and interjections, are frequently dropped or altered by LLM inferencing layers that are trained to produce fluent, grammatically complete output. “Haan,” “okay,” “sahi hai” get absorbed into surrounding context or deleted. For a voice agent tracking conversational turns and consent signals, missing these is not a cosmetic error.
Pure-play ASR systems return the acoustic output without LLM post-processing. The transcript may have more surface-level disfluencies, but it faithfully represents what the speaker said. For downstream NLP, sentiment analysis, compliance monitoring, and voice agent logic, this fidelity is more valuable than grammatical normalization.
What This Means for Benchmark Interpretation
When we report WER across providers, we capture the raw API transcript without modification. For LLM-augmented ASR providers, this means the returned transcript may already differ from the speaker’s actual speech, and the WER score reflects how well the provider’s post-processed output matches dataset reference transcripts, not how accurately it captures the speaker.
This is a structural limitation of any WER-based benchmark applied to LLM-augmented ASR. We flag this explicitly so that teams evaluating ASR for downstream NLP applications understand what they are actually measuring.
Evaluation Infrastructure
Benchmark Flowchart: End-to-End Evaluation Pipeline
The diagram below illustrates the complete end-to-end benchmarking pipeline, from dataset download through API submission to metric computation and result aggregation.
Figure: End-to-end benchmarking pipeline, from dataset download through metric computation. Each stage is designed to preserve evaluation purity: no pre-processing, no post-processing, no optimization not available to a standard customer integration.
Analysis
Interpreting Results: What Good Looks Like
Performance on clean speech datasets, including KathBath, IndicTTS, and FLEURS, establishes a baseline ceiling. These conditions represent best-case acoustics and should be where any ASR system performs strongest. The more diagnostic test is how much a system degrades when moving from clean conditions to noisy telephony (KathBath Noisy) and then to dialectal spontaneous speech (GramVaani).
A system that holds its accuracy reasonably across all three conditions is production-ready for India deployments. A system that performs well only on clean speech is a lab model.
CER adds resolution where WER flattens out, particularly for Tamil and Malayalam where morphological complexity means a single character substitution can change meaning entirely while registering as only one word error. When two systems are close on WER, CER is often the tiebreaker.
All Gnani.ai benchmark numbers are dataset-level aggregates computed on held-out test splits with no overlap between evaluation audio and training data. Metric computation uses jiwer with Unicode normalization and no hypothesis post-processing. What you see in the benchmark is what you get from the API.
Reference
Frequently Asked Questions
Why not use BLEU or ROUGE for ASR evaluation?
BLEU and ROUGE measure n-gram overlap and were designed for machine translation and summarization evaluation. They do not penalize insertions and deletions in the same way as WER, and they do not normalize by reference length in a way that is meaningful for short ASR utterances. WER remains the standard for ASR precisely because it maps directly to the practical cost of a transcript error.
Does WER capture all the ways an ASR system can fail?
No. WER does not measure latency, first-word latency, speaker diarization accuracy, or the handling of code-switched speech (Hindi-English, Tamil-English). These are evaluated separately. WER is a necessary condition for an ASR system to be production-grade; it is not sufficient on its own.
Why does your benchmark differ from the provider’s own published numbers?
Published benchmark numbers from ASR providers are often evaluated on internal test sets, proprietary datasets, or cleaned corpora that differ from production conditions. Our benchmark uses public Indic datasets evaluated through the same production API that a customer would integrate. The conditions are as close to real-world as a controlled evaluation allows.
How do you handle code-switching in Indic language evaluation?
The datasets used here are primarily monolingual, covering Hindi, Tamil, Telugu, Kannada, Bengali, Marathi, Punjabi, Gujarati, Odia, and Malayalam. Code-switching (Hinglish, Tanglish) is a distinct evaluation domain that requires mixed-language corpora and is not covered in this benchmark.
Why do you benchmark CER separately from WER?
Because they measure different things. WER penalizes any token-level mismatch as a complete word error; CER measures the character-level edit distance. For Indic abugidas, where a single character difference changes meaning, CER is often the more diagnostically useful metric. We report both.
Roadmap
Future Evaluation Directions
Benchmark coverage will expand to include streaming transcription latency (P50, P95 first-word latency), speaker diarization accuracy on multi-speaker telephony, and code-switched evaluation sets for Hindi-English and Tamil-English. We are also building evaluation protocols for LLM-augmented ASR that separate acoustic modeling accuracy from LLM post-processing accuracy, so that the two can be assessed independently rather than collapsed into a single WER score.
The goal of a benchmark is not to produce a number. It is to produce a number that means something when a real system goes into production.
Gnani.ai Research Lab
Continue reading.
Explore original research on AI, voice, and language from the Gnani.ai team.


