

Speech Recognition in Rural India: Engineering Automatic Speech Recognition for Background Noise, Low-End Devices, and Compressed Audio on 2G Networks
A Technical Deep-Dive into Indian Language Speech Recognition for Voice AI Engineers, CTOs, and Practitioners Building for Bharat
Deploying automatic speech recognition (ASR) in rural India is not a scaled-down version of deploying it in urban India. It is an entirely different engineering problem. This paper examines the three compounding degradation layers that define rural India speech recognition: (1) high-amplitude, non-stationary background noise from agricultural and domestic environments;(2) the acoustic transfer function of low-cost MEMS and ECM microphones on sub-Rs 5,000 Android and feature phone hardware;and (3) the lossy audio compression artifacts introduced by AMR-NB codec transmission across 2G and 2G-adjacent (EDGE, early VoLTE on congested towers) networks. We explore how these layers interact, why they cause disproportionate failure in low resource Indian language speech recognition models, and what training, architecture, and deployment strategies are currently most effective. We also examine the implications for government-scale deployments including Bhashini, Kisan e-Mitra, and the broader Viksit Bharat voice AI agenda.
Why Rural India Speech Recognition Is a Distinct Engineering Problem
The phrase “low-end device speech recognition”often conjures a simple image: a cheaper phone with a worse microphone. In urban deployment, this mental model is roughly correct, because the remaining pipeline, network transmission, codec, and acoustic environment, is reasonably stable. In rural India, all four variables collapse simultaneously.
Consider the actual signal chain for a farmer in Chhattisgarh calling an IVR-based crop advisory:
- She speaks into a JioPhone or Redmi 2A in an open field with ambient wind and livestock noise.
- The phone’s single MEMS microphone, with an SNR rating of roughly 58 to 62 dB(A), captures that signal without beamforming or directional noise rejection.
- Automatic Gain Control (AGC) on the device compresses the dynamic range unpredictably.
- The audio is encoded in AMR-NB at 5.9 to 7.4 kbps, band-limited to 200 to 3400 Hz, sampled at 8 kHz.
- That signal traverses a congested 2G or early EDGE network with variable packet loss and jitter.
- It arrives at a server-side speech recognition engine likely trained on 16 kHz or 44.1 kHz clean studio recordings.

Figure 1: The Rural India Speech Signal Degradation Chain. Each stage introduces compounding acoustic loss.
Research has shown that even robust multilingual models like IndicWav2Vec degrade to a prohibitively high 40.94% Word Error Rate when exposed to real-world clinical telephony audio from rural India (Bhanushali et al., arXiv:2512.16401). That figure is from a controlled study. Real-world deployments are worse.
The GramVaani corpus, collected across village communities in UP, MP, Bihar, and Jharkhand, is the benchmark that captures this signal chain honestly. On GramVaani, Gnani.ai’s ASR model achieves 24.94% WER, the lowest of any model evaluated and nearly 5 points better than Microsoft Azure STT. Section 6 unpacks what drives that gap.
The Noise Layer: How Non-Stationary Acoustics Break Speech Recognition in Rural India
2.1 What the Noise Actually Looks Like
Urban noise is, paradoxically, more tractable for speech recognition. Traffic, HVAC, and crowd babble produce relatively stationary noise floors that spectral subtraction handles reasonably well. But research shows engines achieving 95 percent accuracy on clean benchmarks can collapse below 70 percent in recordings filled with non-stationary noise sources (Deepgram, 2025).
Rural India sound environments are dominated by non-stationary noise: cattle vocalizations, agricultural machinery with variable RPM, wind turbulence (particularly problematic because it directly couples into microphone diaphragms), children, radio or TV playing in adjacent rooms, and sudden high-amplitude transients like a diesel pump engaging. These noise sources are spectrally broadband and temporally unpredictable, which defeats most classical noise suppression approaches.
2.2 SNR Thresholds and Their Effect on WER
Research shows that at 0 dB SNR, noise dominates over packet loss as the driver of WER, and models trained on noise-network distorted speech withstand packet loss under 15% and SNR above 5 dB without significant degradation (Frontiers in Signal Processing, 2022).
Rural India speech recording scenarios regularly produce SNR values between 0 and 10 dB. Analysis of over 10,000 real-world agricultural field recordings from the Farmer.Chat platform between June 2024 and February 2025 confirmed that audio quality challenges are endemic to these environments (Digital Green / Farmer.Chat, arXiv:2602.03868).
2.3 The AGC Interference Problem
Low-end Android devices and feature phones universally employ Automatic Gain Control as part of their audio front-end. AGC is designed to normalize recording levels, but in noisy environments it introduces a specific failure mode: when ambient noise rises, AGC boosts the entire signal, including the noise floor. The built-in microphones in mobile devices are manufactured with customized AGC, active noise cancellation, and noise rejection strategies, and the effect of AGC might significantly reduce accuracy of sound level measurement, with unpredictable influence on specific frequency components (International Journal of Speech Technology, 2021).
For an ASR speech recognition system, this means the feature extraction pipeline, whether MFCC, filterbank, or raw waveform, receives a signal whose statistical properties have been non-linearly transformed by hardware the model has no knowledge of. Data augmentation must explicitly model this.
The Device Layer: How Low-End Android Microphones Degrade Indian Language Speech Recognition
3.1 The Hardware Reality of Low-End Device Speech Recognition
The Indian smartphone market below Rs 8,000 is dominated by devices that share a hardware profile: a single-capsule MEMS microphone positioned on the bottom edge or rear panel, with no secondary microphone for beamforming or noise cancellation. This is categorically different from the dual or triple microphone arrays in mid-range devices that modern ASR systems implicitly assume.
Entry-level MEMS microphones operate at 58 to 62 dB(A) SNR; premium mid-range device microphones at 65 to 72 dB(A). That 10 to 14 dB gap represents a substantial reduction in recoverable speech signal, particularly for fricatives and unvoiced stops that depend on high-frequency energy (Kingstate MEMS specifications).
Feature phones including the JioPhone 2 use ECM (Electret Condenser Microphone) capsules that are even more acoustically limited, and remain in active use for IVR-based voice services across rural India at a signal quality floor most published benchmarks do not test against.
The Compression Layer: How 2G Network Codec Compression Destroys Speech Recognition Accuracy
4.1 The AMR-NB Codec and Its Acoustic Consequences
AMR-NB (Adaptive Multi-Rate Narrowband) is the dominant speech encoding standard on 2G GSM networks in India, operating at eight bit rates from 4.75 to 12.2 kbps (VoiceAge / ITU-T TS 26.071). Under good network conditions calls encode at 12.2 kbps; under congestion the network drops to 5.9 or 4.75 kbps.
The AMR codec uses sampling at 8 kHz filtered to 200 to 3400 Hz. Under network stress, mean opinion scores drop from 4.14 to 3.79 for AMR at 12.2 kbit/s (Wikipedia AMR-NB;ITU-T G.711 comparison). MOS scores tell you about perceptual quality;what they do not tell you is the specific spectral damage to phoneme boundaries that determines speech recognition accuracy.

Figure 2: AMR-NB bandwidth truncation at 3400 Hz and its impact on Indic language phoneme classes. Retroflex and aspirated consonants, phonemically contrastive across all major Indian languages, lose critical spectral cues.
4.2 Bitrate Reduction and WER Degradation
Research confirms that 8 kbps encoding has no spectral information above 4 kHz (arXiv:2002.00122). A model trained on wideband 16 kHz audio and exposed to 8 kHz telephony audio without acoustic model adaptation will encounter systematic acoustic mismatch across the entire spectrum. Research has established that server-side ASR should not be carried out by simply decimating received signals to 8 kHz and applying existing narrowband acoustic models;codec effects are not equivalent to simple downsampling (Bauer &Fingscheidt, WTIMIT, LDC2010S02).
4.3 The EDGE and 2G-Adjacent Problem
The real 2026 condition is “2G-adjacent”: EDGE networks nominally capable of higher data rates but congested enough that packet loss and jitter approach 2G behavior, with VoLTE on overloaded towers introducing jitter patterns AMR’s error concealment was not designed to handle.
The combined effect of jitter and packet loss significantly increases speech recognition WER. Speech recognition systems trained on noise-network distorted speech show minimized error rates compared to clean-speech-trained models, but improvement decreases when jitter exceeds 30% of frame delay and packet loss exceeds 15% (Frontiers in Signal Processing, 2022). Few published benchmarks combine all three degradation types simultaneously.
The Language and Dialect Layer: Low Resource Indian Language Speech Recognition
5.1 The Training Data Gap
India has 121 languages and 125 crore speakers, yet most are low resource in terms of pretrained speech recognition models. The Vakyansh project created 14,000 hours across 23 Indic languages (Chadha et al., arXiv:2203.16512), averaging 600 hours per language. Standard English ASR models train on 60,000 to 960,000 hours. The speech recognition performance gap is not linear.
Most Indic training corpora were collected from urban speakers reading prompted text at 16 kHz or higher in reasonably clean environments. This creates systematic domain mismatch with the actual deployment population: rural speakers using conversational, spontaneous speech on low-quality audio chains, often in non-standard dialectal forms.
5.2 Dialect Variation in Rural India Speech
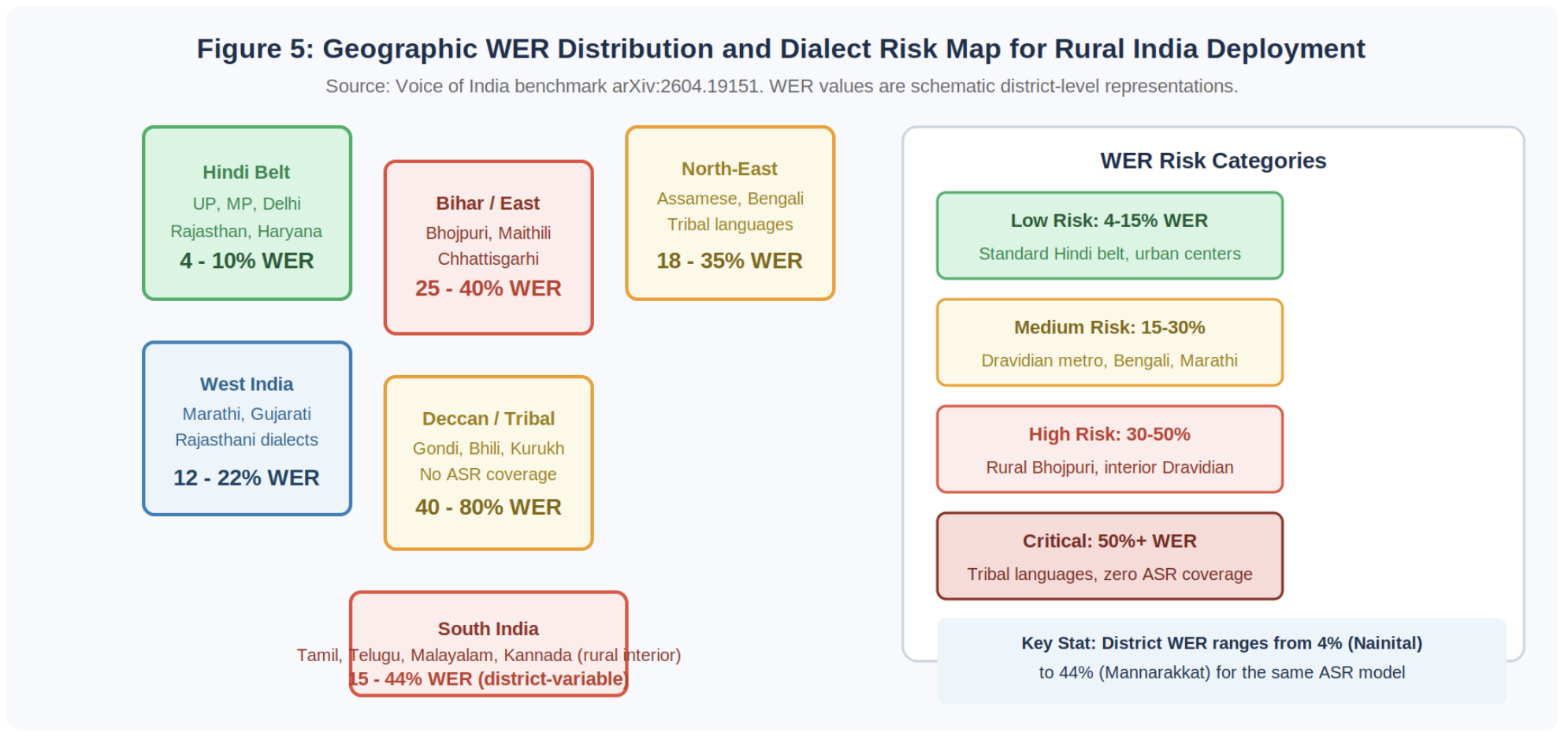
Figure 5: Schematic representation of geographic WER distribution. District-level data from Voice of India benchmark (arXiv:2604.19151) shows WER ranging from 4% to 44% for the same ASR model across districts.
District-level WER ranges from 4% in some northern districts to 44% in others, with the highest error rates in South India and North Bihar, reflecting underrepresented languages including Maithili and Bhojpuri (Voice of India, arXiv:2604.19151).
Bhojpuri has more than 50 million speakers, predominantly rural, yet Word Error Rate remains at 33.3% compared to 15% for standard Hindi, underscoring the gap between mainstream model training and actual deployment populations (arXiv:2506.09653).
Benchmark Data: Speech Recognition Accuracy Across Indian Languages and Models
6.1 GramVaani: Why This Is the Benchmark That Matters
Before examining individual model numbers, it is worth establishing which benchmark actually measures what this paper is about. Most published ASR benchmarks use clean studio recordings, prompted speech, or field audio that has been quality-filtered. They are useful for comparing model architectures. They are not useful for predicting how a model will perform on a PM-KISAN helpline call from Bihar.
GramVaani, collected by the GramVaani organization and IIT Delhi across village communities in Uttar Pradesh, Madhya Pradesh, Bihar, and Jharkhand, is the exception. It captures spontaneous Hindi from rural users into low-end handsets over mobile networks, in agricultural noise environments. The corpus does not allow benchmark inflation through clean-audio evaluation. A model that performs well on GramVaani has genuinely learned to handle the compounding degradation this paper describes. One that was optimized purely on studio data will fail on it, and the numbers make that failure visible.
The table below shows the full model comparison on GramVaani. The sections that follow examine the broader benchmark landscape and what the gap between GramVaani performance and clean-audio benchmarks means for practitioners making deployment decisions.
Table 3: GramVaani WER – Gnani.ai Internal Benchmark, May 2026
| Model | GramVaani WER | vs. Best |
|---|---|---|
| Gnani.ai ASR Model | 24.94% | Best |
| Sarvam Saarika v3.0 | 26.12% | +1.18 pp |
| Sarvam Saarika v2.5 | 26.75% | +1.81 pp |
| Microsoft Azure STT | 29.88% | +4.94 pp |
| Deepgram | 35.20% | +10.26 pp |
| ElevenLabs Scribe v1 | 37.46% | +12.52 pp |
Gnani.ai internal benchmark evaluation, May 2026. GramVaani Hindi dataset. WER = Word Error Rate; lower is better. pp = percentage points above best score.
6.2 Agricultural and Field-Condition Results
Evaluation of over 10,000 real-world agricultural field recordings across Hindi, Telugu, and Odia reveals performance variations with Hindi achieving the best overall performance at a WER of 16.2% while Odia presents the greatest challenges with a best WER of 35.1%. Speaker diarization with best-speaker selection can reduce WER by up to 66% (Digital Green / Farmer.Chat, arXiv:2602.03868).
Even the 16.2% WER for Hindi represents agricultural field recordings, not the noisier compressed telephony pipeline. In end-to-end telephony deployments with AMR-NB audio, Hindi WER routinely exceeds 25 to 35% on production traffic.
Table 1: ASR WER Comparison Across Indian Languages and Models
| Language | Google STT | Sarvam AI | Whisper | AI4Bharat | Condition |
|---|---|---|---|---|---|
| Hindi (field) | 5% | 8% | 12% | 11% | Agricultural field |
| Telugu | 22% | 46.5% | 62% | N/A | Agricultural field |
| Odia | 70.7% | 35.8% | 55%+ | 64.8% | Agricultural field |
| Bhojpuri | N/A | N/A | 45% | 33.3% | Best available model |
| Hindi (telephony) | 25-35%* | 25-35%* | 35-45%* | 25-35%* | AMR-NB 8kHz prod* |
* Estimated production telephony WER based on clean-audio benchmark degradation patterns. Vendor-published numbers are clean-audio benchmarks only.
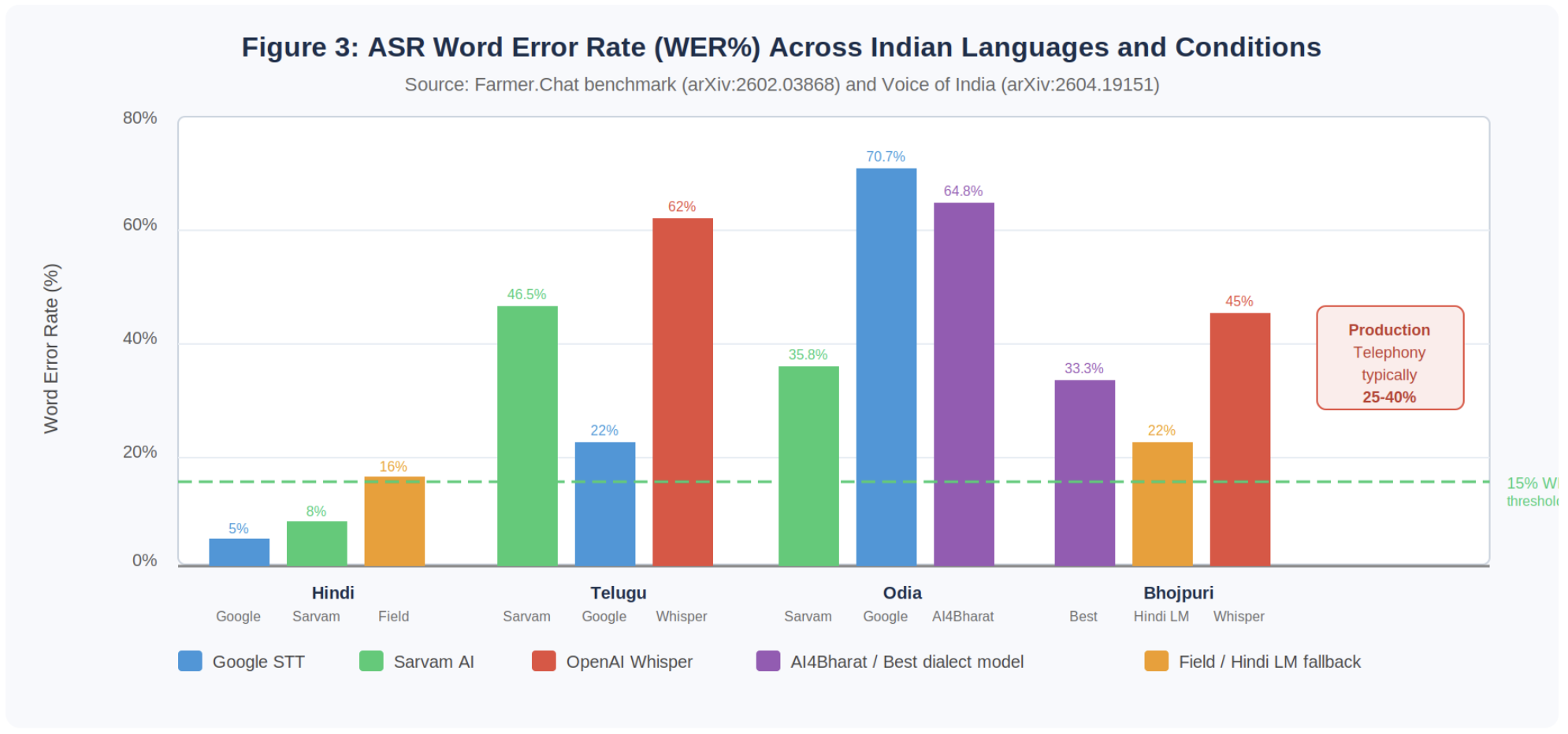
Figure 3: ASR WER (%) comparison across Indian languages and models. Green dashed line at 15% WER represents an indicative production-grade threshold. Telephony conditions (rightmost bar group) represent estimated production floor.
6.3 Sarvam and Google ASR Performance in Low-Resource Indian Language Conditions
In agricultural field recordings across Telugu, Sarvam AI achieved a WER of 46.5% but a notably low agricultural word-weighted error rate of 32.5%, suggesting relatively good preservation of domain-specific terminology. For Odia, both Sarvam AI and Spring Labs achieved 35.8% WER, while Google STT dropped to 70.7% WER for Odia, illustrating the severity of the low-resource language challenge (Farmer.Chat benchmark, 2026).
Sarvam’s Saaras V3 achieves approximately 19% WER on the IndicVoices benchmark and handles code-mixed speech (Sarvam AI, 2026).
Technical Mitigation Strategies: How to Build Speech Recognition for Rural India
The GramVaani benchmark result for Gnani.ai’s ASR model is not a product of better base architecture. It is a product of training decisions: specifically, the decision to treat rural India conditions as the primary design constraint rather than an afterthought. The strategies below describe what that looks like in practice.

Figure 4: Recommended ASR training and inference architecture for rural India deployment. Training pipeline (top) uses multi-condition augmentation. Inference pipeline (bottom) includes confidence gating and on-device LoRA adaptation.
7.1 Training Data Augmentation for the Three-Layer Problem
The most evidence-backed intervention is multi-condition training with augmentation that accurately simulates the deployment audio chain:
Codec simulation augmentation: Apply FFMPEG-based AMR-NB encoding at all eight bit rates (4.75-12.2 kbps) to training audio before feature extraction. Codec simulation augmentation has been validated as an effective technique for telephony speech recognition (Lee et al., APSIPA 2019). This is a baseline requirement, not an optimization.
Noise augmentation with non-stationary sources: MUSAN-style augmentation is insufficient. Training data must include agricultural profiles: wind, cattle, diesel engines, hand pumps, open-air markets mixed at 0-10 dB SNR.
Resampling to 8 kHz: Include 8 kHz resampled audio with MFCC filterbank configuration (20 filterbanks, 64 ms frames, 20 ms shifts). Models never exposed to 8 kHz audio during training exhibit systematic degradation that cannot be recovered at inference.
Microphone variability simulation: Include training samples processed through simulated low-SNR microphone transfer functions, modeling the noise floor itself, not just reverberation via RIR.
7.2 On-Device and Edge Adaptation
For deployments with data residency constraints, on-device LoRA adaptation with multi-domain Experience Replay achieves a 17.1% relative WER improvement and reduces catastrophic forgetting by 55% without transmitting raw audio off-device (Bhanushali et al., arXiv:2512.16401), making it particularly relevant for Bhashini and Jan Dhan-adjacent deployments.
Practical implementation requires a model fitting 1 to 2 GB RAM on Android hardware. Quantized Whisper Small (39M parameters, approximately 40 MB at 8-bit) or purpose-built compact architectures following Squeezeformer or Conformer-Small are viable candidates.
7.3 Speech Enhancement as a Preprocessing Stage
The denoising paradox is real but not universal. The key distinction is whether enhancement is applied before a clean-trained model, or whether the model has co-trained with the enhancement stage. Whether noise reduction improves ASR accuracy varies significantly across models;some approaches can inadvertently amplify demographic biases through selective acoustic filtering (Agarwal &Misra, arXiv:2512.17562).
7.4 Language Model Integration for Dialectal Robustness
A 5-gram KenLM trained on dialect-specific text corpora provides meaningful WER reduction in hybrid speech recognition systems. On GramVaani and similar datasets, LM integration with domain-specific data outperforms wav2vec baselines (Verma et al., Interspeech 2023). Shallow fusion at beam search time is the most deployment-friendly strategy: no acoustic model retraining required, and the LM updates as new dialectal text becomes available.
Government Deployment: Bhashini, IVR Speech Recognition, and the Viksit Bharat Voice AI Agenda
8.1 Bhashini’s Infrastructure and Its Acoustic Gap
Bhashini enables real-time transcription and translation of speech in 22 Indian languages and has been deployed in rural schools for ASR-based pronunciation feedback, with offline functionality for remote areas (Bhashini Division, MeitY, 2024). The platform supports 36 languages under MeitY’s National Language Translation Mission, with integrations including ONDC’s Saarthi application.
8.2 Government Voice AI Use Cases That Demand Rural-Grade ASR
Government bodies including UIDAI, PM-KISAN, and local municipalities are deploying IVR-based voice bots powered by Bhashini, Reverie, and AI4Bharat to help citizens navigate welfare schemes and subsidies (People+AI, 2025). The PM-KISAN helpline, Jan Dhan enquiry IVR, and crop insurance verification are all active deployments where speech recognition accuracy directly determines whether a farmer receives correct information.
Kisan e-Mitra has handled over 95 lakh farmer queries, with 8.48 crore Farmer IDs generated under the Digital Agriculture Mission’s AgriStack as of February 2026 (India AI Impact Summit 2026). At that scale, a 5 percentage point WER improvement translates into millions of correctly captured queries.
8.3 Current State and Open Problems
A rural banking assistant using Sarvam’s Saaras ASR combined with Bulbul TTS enabled farmers to query KCC loan balances in dialect-heavy Hindi (Inc42, 2026). Until WER numbers on AMR-NB compressed audio at 5.9 kbps with rural noise are published by any vendor, practitioners cannot make evidence-based decisions about off-the-shelf vs. fine-tuned vs. hybrid systems.
Practical Speech Recognition Deployment Checklist for Voice AI Engineers Building for India
For teams building ASR for rural India conditions, these engineering decisions are the most consequential. All recommendations are derived from peer-reviewed literature cited throughout this paper.
Table 2: Engineering Checklist for Rural India ASR Deployment
| Engineering Layer | Required Action | Priority |
|---|---|---|
| Audio ingestion | Accept 8 kHz mono natively. Never upsample before ASR without retraining. | Critical |
| Codec augmentation | AMR-NB simulation at 4.75, 5.9, 6.7, 7.4 kbps on 40%+ of training data. | Critical |
| Noise augmentation | Rural noise profiles (wind, cattle, machinery) at 0-15 dB SNR. Non-stationary sources. | Critical |
| Dialect coverage | 50-100 hours dialect-specific data for Bhojpuri, Maithili, Chhattisgarhi, Marwari. | High |
| Language model | 5-gram KenLM with domain vocab. Shallow fusion at beam search decode. | High |
| Confidence gate | Threshold-based fallback to re-prompt, menu, or human agent transfer. | High |
| On-device adapt. | LoRA-based on-device adaptation (Whisper Small, ~40 MB quantized) for privacy-constrained deployments. | Medium |
| Speech enhancement | Avoid standalone denoising pre-processing on clean-trained models. Use multi-condition training instead. | Avoid naive use |
Conclusion: Rural India Speech Recognition Is Solvable, But Not Accidentally
Rural India speech recognition is not an unsolvable problem. The challenge is systemic: compounding acoustic degradation from microphone hardware, codec compression, network artifacts, and dialect mismatch, all of which standard training pipelines ignore.
Each degradation layer has a known mitigation strategy. Codec augmentation addresses the compression layer. Multi-condition noise training addresses the acoustic environment. Dialect-specific fine-tuning with LM integration addresses language mismatch. On-device LoRA adaptation addresses domain shift in production.
The Viksit Bharat voice AI deployment agenda, including Bhashini-powered IVR and Kisan e-Mitra, will succeed or fail on exactly these engineering decisions. A farmer asking about her PM-KISAN installment in a field in Bihar should receive the same speech recognition accuracy as an urban professional in a quiet office. That parity is achievable with methodical, acoustically-informed engineering.
Gnani.ai’s ASR model achieving 24.94% WER on GramVaani, the most acoustically demanding rural India benchmark, is evidence that this engineering approach works. The gap between that number and the 29-37% range of global competitors is not architectural. It is methodological.
Frequently Asked Questions: Speech Recognition in Rural India
References
All papers are freely accessible at arxiv.org unless otherwise noted.
- 01Chadha et al. (2022). Vakyansh: ASR Toolkit for Low Resource Indic Languages. arXiv:2203.16512.
- 02Diwan et al. (2021). Multilingual and Code-Switching ASR Challenges for Low Resource Indian Languages. Interspeech 2021. arXiv:2104.00235.
- 03Javed et al. (2022). Towards Building ASR Systems for the Next Billion Users. AAAI 2022, Vol. 36.
- 04Voice of India Benchmark (2025). A Large-Scale Benchmark for Real-World Speech Recognition. arXiv:2604.19151.
- 05Bhanushali et al. (2024). Privacy-Preserving On-Device Continual Adaptation of ASR for Clinical Telephony. arXiv:2512.16401.
- 06Digital Green / Farmer.Chat (2026). Benchmarking Speech Recognition for Indian Languages in Agricultural Contexts. arXiv:2602.03868.
- 07ITU-T / 3GPP. AMR-NB Codec Specification. TS 26.071, TS 26.090. VoiceAge Corporation.
- 08Bauer & Fingscheidt (2010). WTIMIT: TIMIT Transmitted Over Wideband Telephony. LDC2010S02.
- 09Verma, V., et al. (2023). ASR for Low Resource and Multilingual Noisy Code-Mixed Speech. Interspeech 2023.
- 10Sivaraman et al. (2020). Speech Bandwidth Expansion for Speaker Recognition on Telephony Audio. Odyssey 2020.
- 11Lee et al. (2019). Audio Codec Simulation Data Augmentation for Telephony Speech Recognition. APSIPA 2019.
- 12Recognizing Every Voice (2025). Towards Inclusive ASR for Rural Bhojpuri Women. arXiv:2506.09653.
- 13Dialect Matters (2025). Cross-Lingual ASR Transfer for Low-Resource Indic Language Varieties. arXiv:2601.04373.
- 14Agarwal & Misra (2025). When De-noising Hurts: Speech Enhancement Effects on Medical ASR. arXiv:2512.17562.
- 15Frontiers in Signal Processing (2022). ASR Performance on Integrated Noise-Network Distorted Speech.
- 16Sarvam AI (2026). Saaras V3: ASR for Indian Languages. sarvam.ai/blogs/asr.
- 17People+AI (2025). Voice AI in India: A Maturing Market. peopleplus.ai.
- 18Bhashini Division, MeitY (2024). No Indian Left Behind: Bhashini, the Language of Inclusion.
- 19India AI Impact Summit 2026. Can AI Transform Agriculture for Viksit Bharat 2047?
- 20Pillai, Manohar et al. (2024). Multistage Fine-tuning Strategies for Low-resource ASR. arXiv:2411.04573.
This paper was researched and written in April 2026. All WER figures cited are from published research or publicly disclosed model evaluations. Production WER in telephony deployments may differ substantially from benchmark figures.


